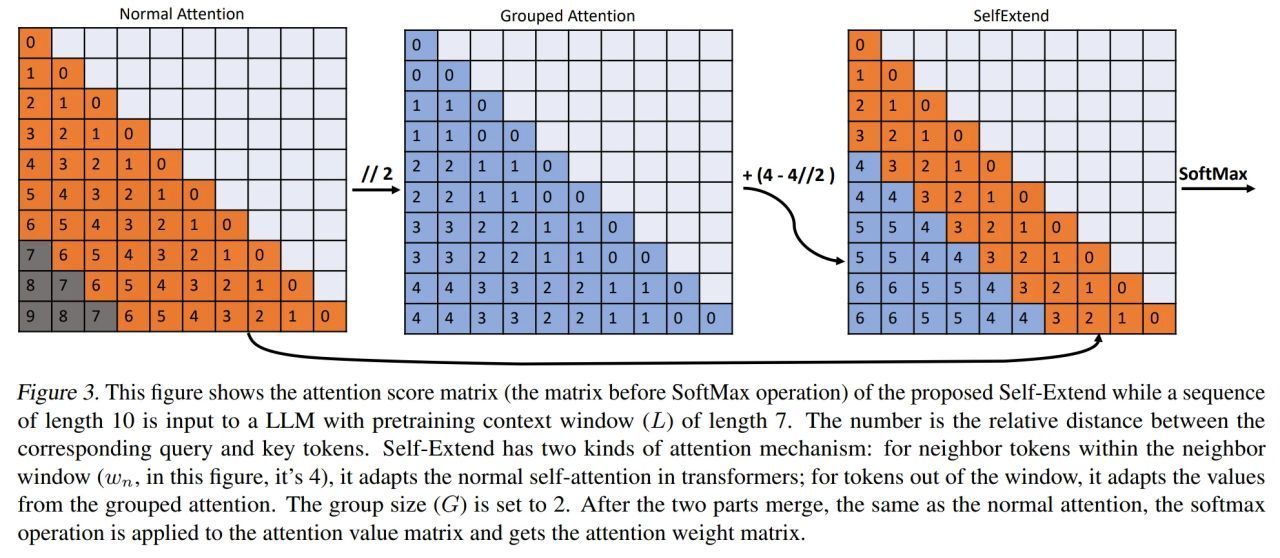
With only four lines of code modification, the proposed method can effortlessly extend existing LLMs’ context window without any fine-tuning. This work elicits LLMs’ inherent ability to handle long contexts without fine-tuning. The limited length of the training sequence during training may limit the application of Large Language Models (LLMs) on long input sequences for inference.
In this work, we argue that existing LLMs themselves have inherent capabilities for handling long contexts. Based on this argument, we suggest extending LLMs’ context window by themselves to fully utilize the inherent ability.We propose Self-Extend to stimulate LLMs’ long context handling potential. The basic idea is to construct bi-level attention information: the group level and the neighbor level. The two levels are computed by the original model’s self-attention, which means the proposed does not require any training. With only four lines of code modification, the proposed method can effortlessly extend existing LLMs’ context window without any fine-tuning. We conduct comprehensive experiments and the results show that the proposed method can effectively extend existing LLMs’ context window’s length.